Socrata ELT
Socrata Table Ingestion Flow¶
The Update-data DAGs for (at least) Socrata tables follow the pattern below: * Check the metadata of the table's data source (via api if available, or if not, by scraping where possible) * If the local data warehouse's data is stale: * download and ingest all new records into a temporary table, * identify new records and updates to prior records, and * add any new or updated records to a running table of all distinct records * If the local data warehouse's data is as fresh as the source: * update the freshness-check-metadata table and end
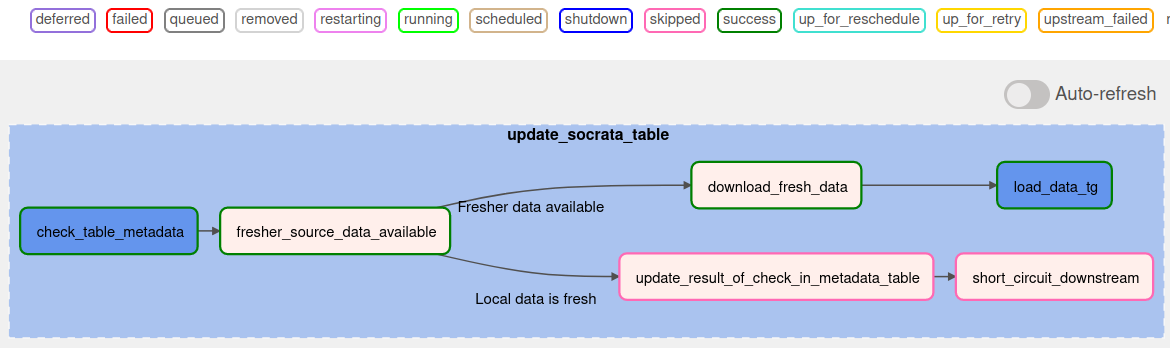
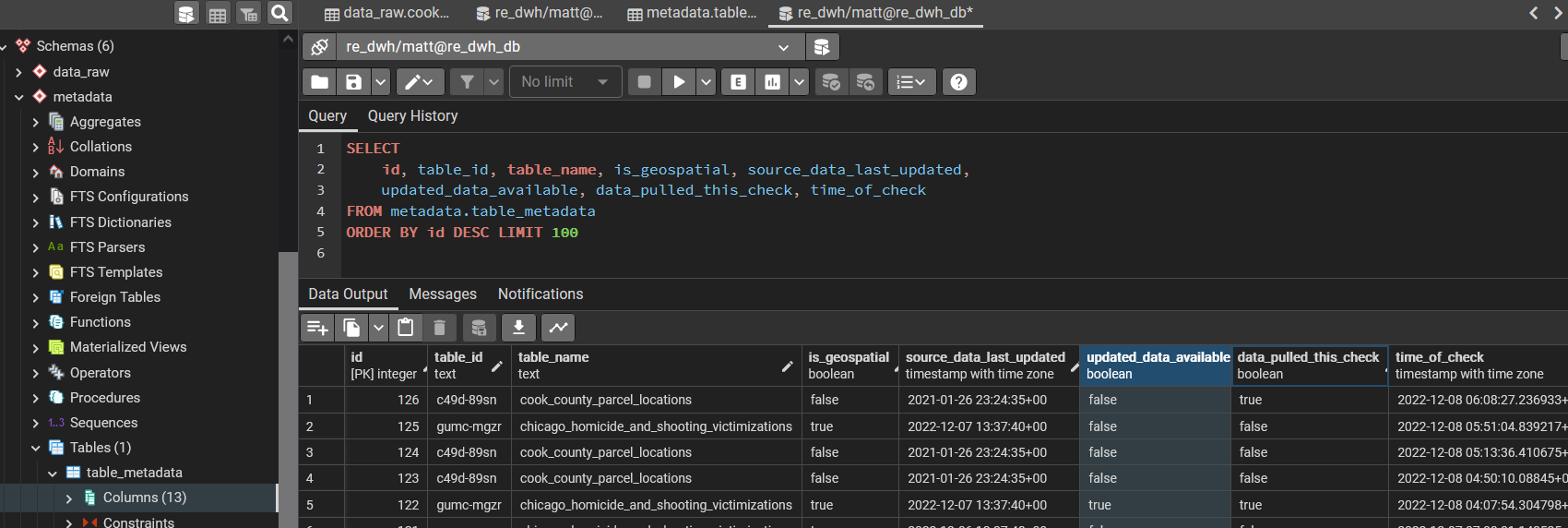
Before downloading potentially gigabytes of data, we check the data source's metadata to determine if the source data has been updated since the most recent successful update of that data in the local data warehouse. Whether there is new data or not, we'll log the results of that check in the data_warehouse's metadata.table_metadata table.

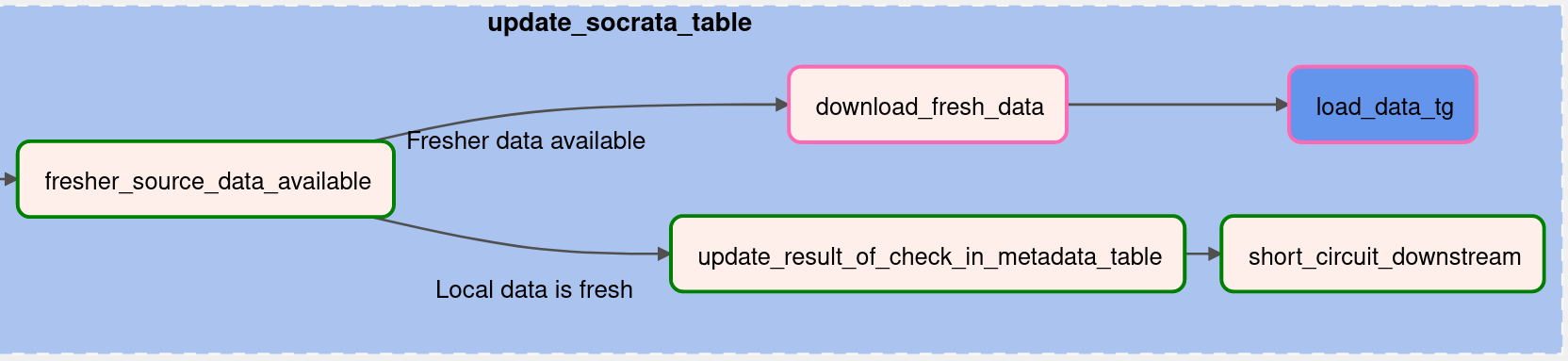
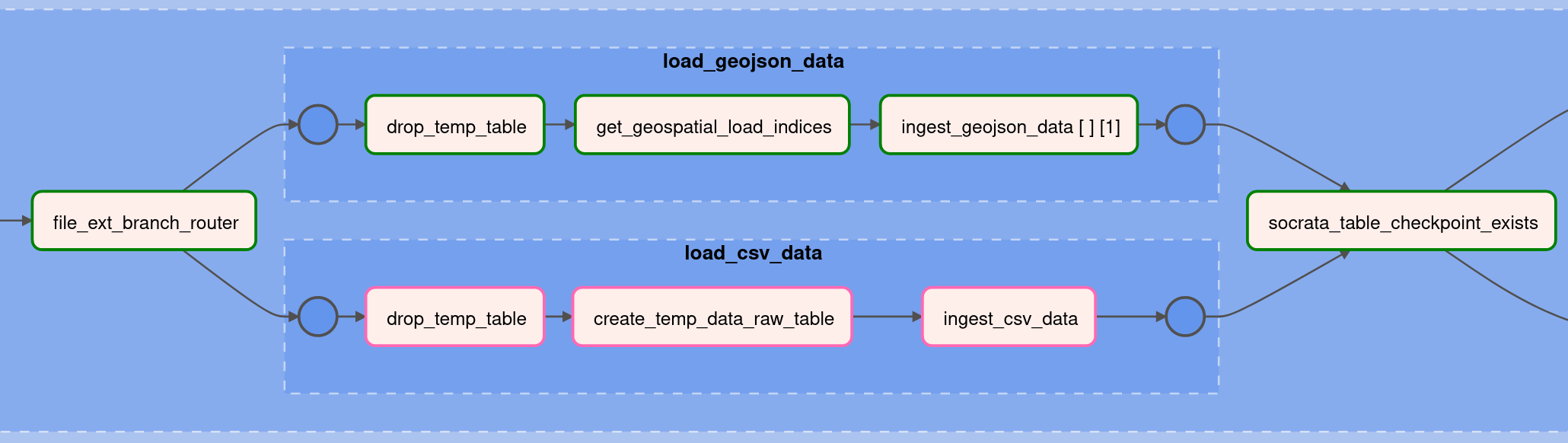
If the data source's data is fresher than the data in the local data warehouse, the system downloads the entire table from the data source (to a file in the Airflow-scheduler container) and then runs the load_data_tg TaskGroup, which:
-
Loads it into a "temp" table (via the appropriate data-loader TaskGroup).
-
Creates a persisting table for this data set in the
data_rawschema if the data set is a new addition to the warehouse. -
Checks if the initial dbt data_raw deduplication model exists, and if not, the
make_dbt_data_raw_modeltask automatically generates a data-set-specific dbt data_raw model file.
-
Compares all records from the latest data set (in the "temp" table) against all records previously added to the persisting
data_rawtable. Records that are entirely new or are updates of prior records (i.e., at least one source column has a changed value) are appended to the persistingdata_rawtable.- Note: updated records do not replace the prior records here. All distinct versions are kept so that it's possible to examine changes to a record over time.
-
The
metadata.table_metadatatable is updated to indicate the table in the local data warehouse was successfully updated on this freshness check.
Those tasks make up the
load_data_tgTask Group.
If the local data warehouse has up-to-date data for a given data source, we will just record that finding in the metadata table and end the run.
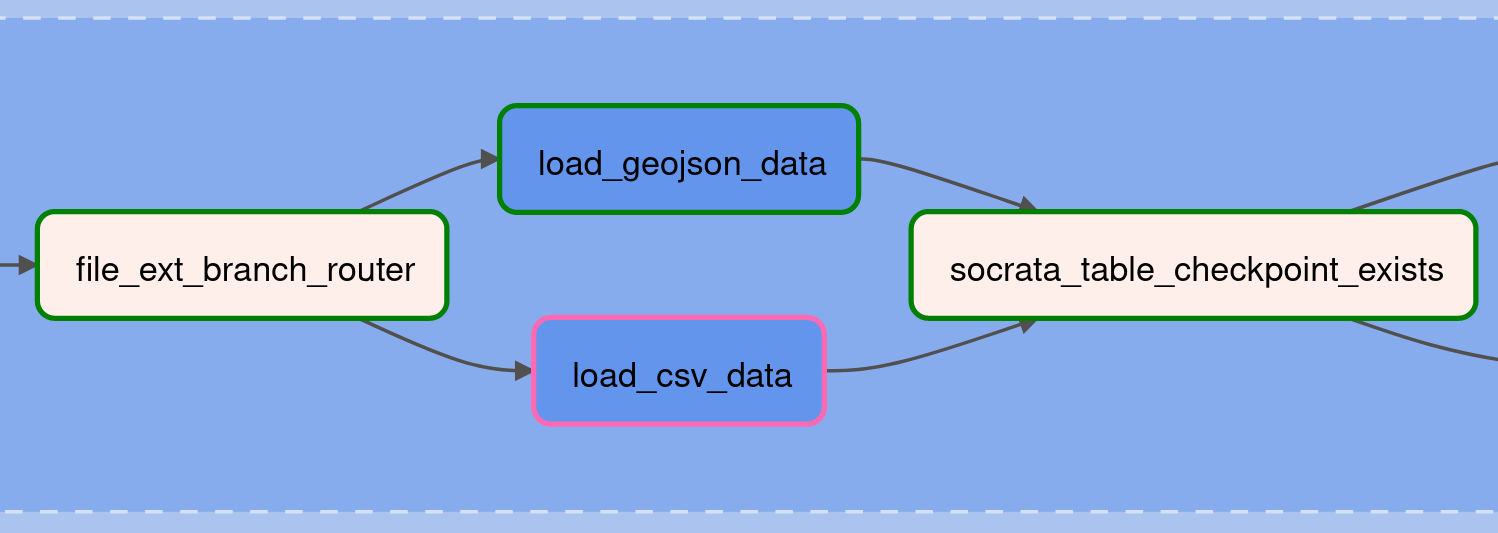
Data Loader task_groups¶
Tables with geospatial features/columns will be downloaded in the .geojson format (which has a much more flexible structure than .csv files), while tables without geospatial features (ie flat tabular data) will be downloaded as .csv files. Different code is needed to correctly and efficiently read and ingest these different formats. So far, this platform has implemented data-loader TaskGroups to handle .geojson and .csv file formats, but this pattern is easy to extend if other data sources only offer other file formats.
Many public data tables are exported from production systems, where records represent something that can change over time. For example, in this building permit table, each record represents an application for a building permit. Rather than adding a new record any time the application process moves forward (e.g., when a fee was paid, a contact was added, or the permit gets issued), the original record gets updated. After this data is updated, the prior state of the table is gone (or at least no longer publicly available). This is ideal for intended users of the production system (i.e., people involved in the process who have to look up the current status of a permit request). But for someone seeking to understand the process, keeping all distinct versions or states of a record makes it possible to see how a record evolved. So I've developed this workflow to keep the original record and all distinct updates for (non "temp_") tables in the data_raw schema.
This query shows the count of new or updated records grouped by the data-publication DateTime when the record was new to the local data warehouse.
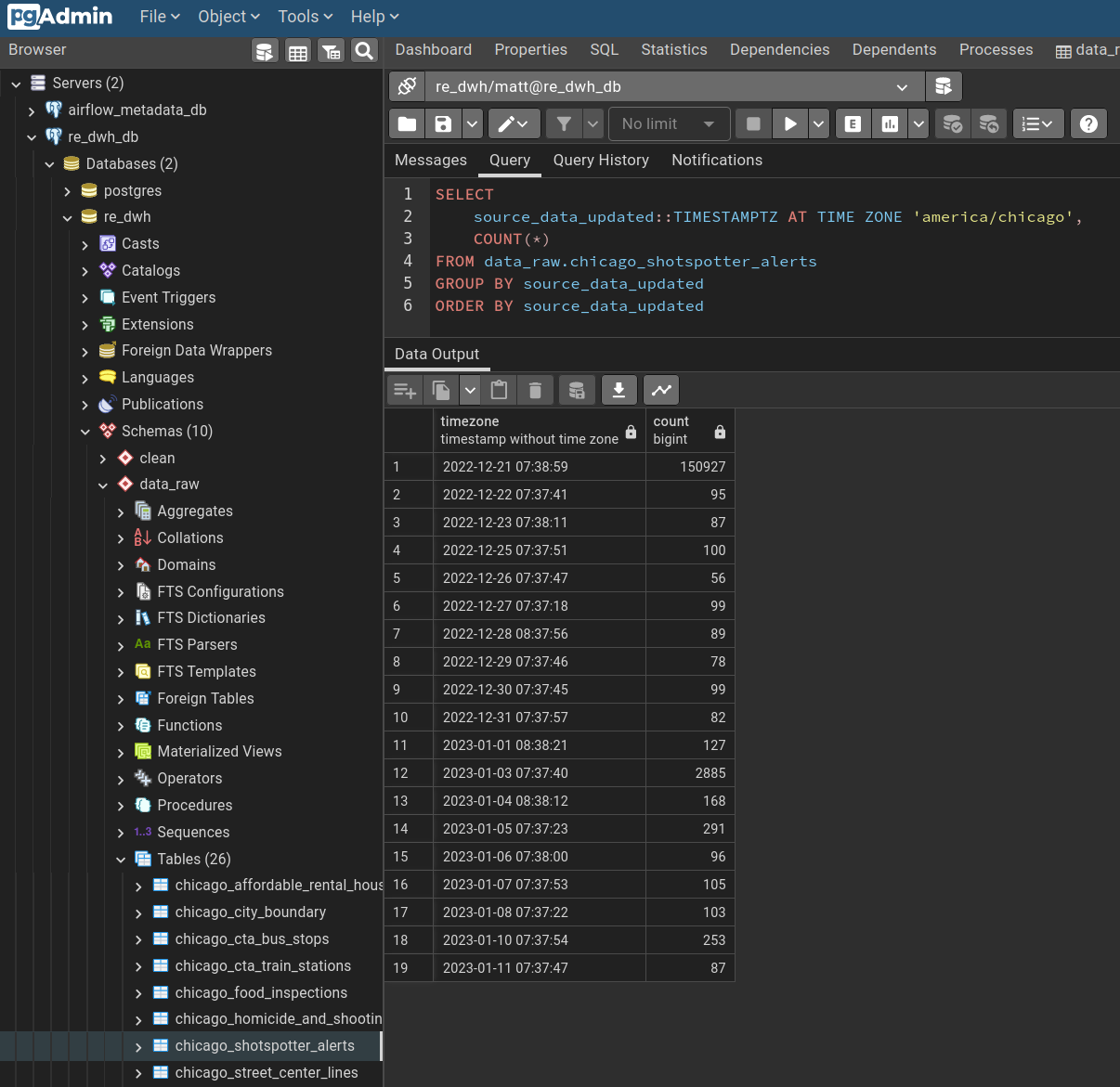
Fig: People really love using fireworks on New Years, and those alerts typically get updated after review.